CVA6 乱序执行原理
CVA6 乱序执行原理
流水线简介
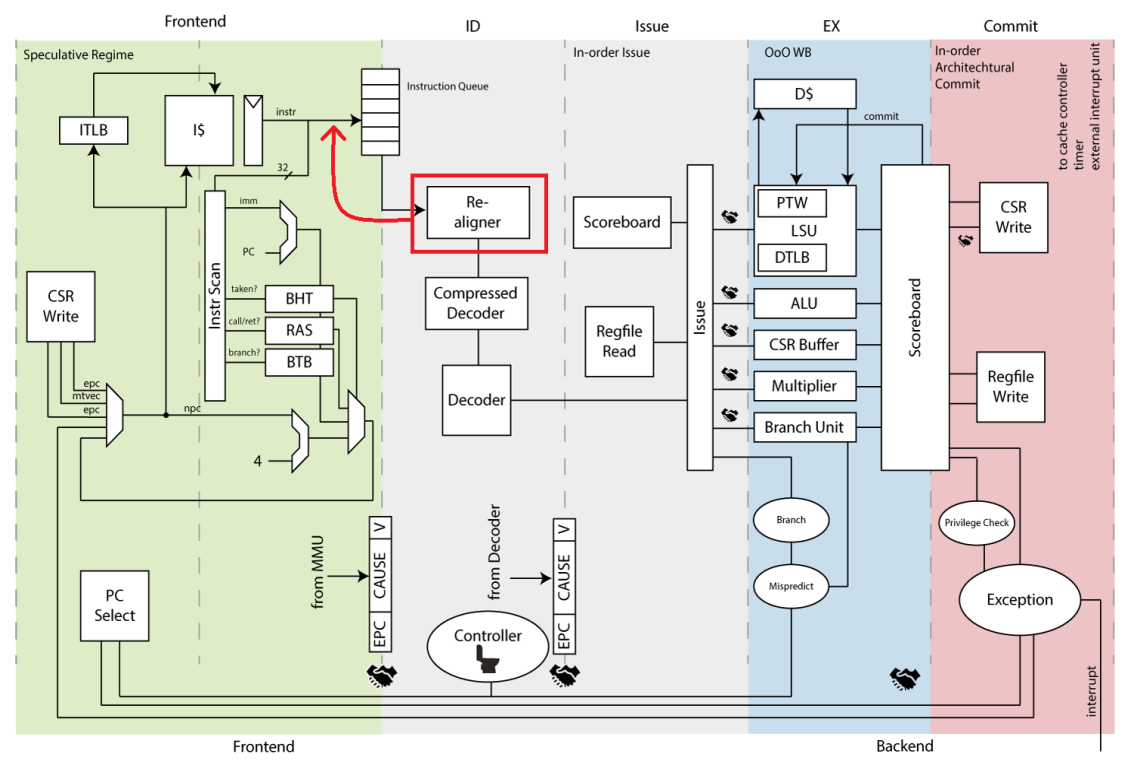
CVA6 流水线分为前端(Frontend)和后端(Backend),通过 Instruction Queue 来实现前后端分离
- 前端负责取指令,将取得的指令放入
Instruction Queue - 后端从
Instruction Queue读取指令,进行译码,发射,执行,提交等操作。
CVA6 在后端微架构设计上有以下特点
- 顺序发射(目前版本只能单发射,双发射版本没有合并到主线)
- DataCapture 模式(所有操作数准备好后,才能离开发射队列)
- 乱序执行(乱序了但没有完全乱序)
- 一个 ALU,一个 CSR,一个 BRU,一个 LSU,一个 Multiply
- 各个执行单元之间没有依赖,可以独立执行,从而实现指令的乱序执行
- 实际上就是 ALU、BRU(单周期操作) 和 LSU、Multiply(多周期操作) 之间的乱序执行
- 各个执行单元的结果写入 ScoreBoard 中对应的项
- 顺序提交
- 每次读取 ScoreBoard 中最老的指令进行提交
- 在提交阶段检查中断和异常(为了实现精确中断)
- 对于一些指令有特殊处理( csr 指令,访存指令)
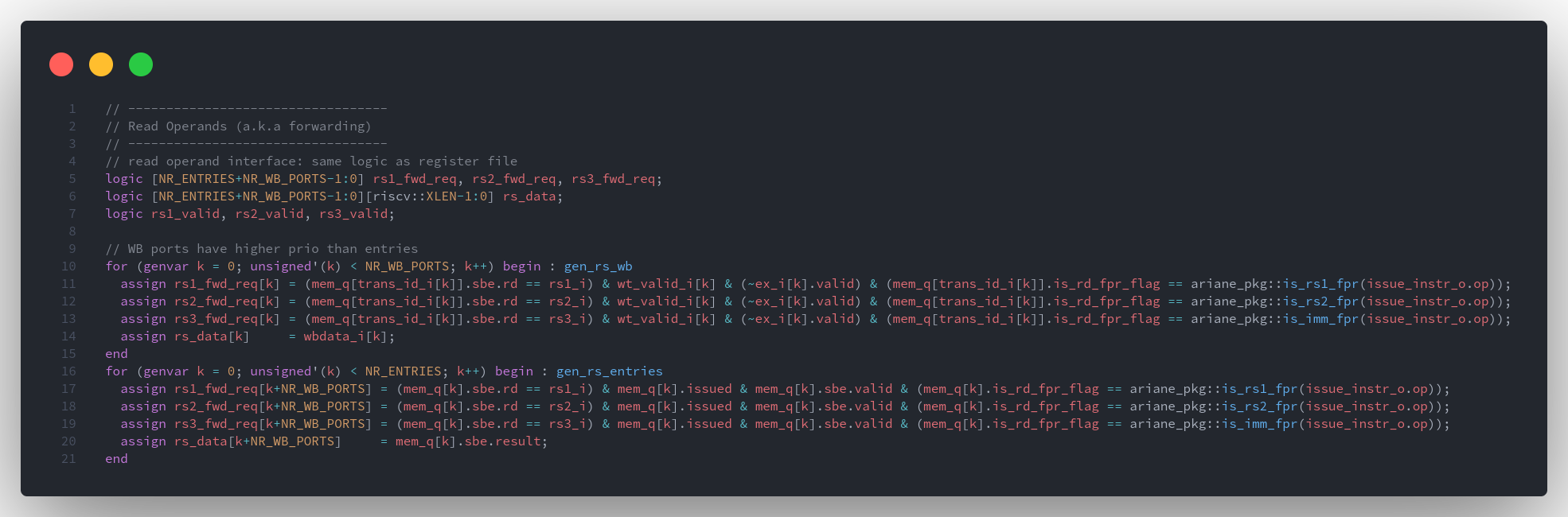
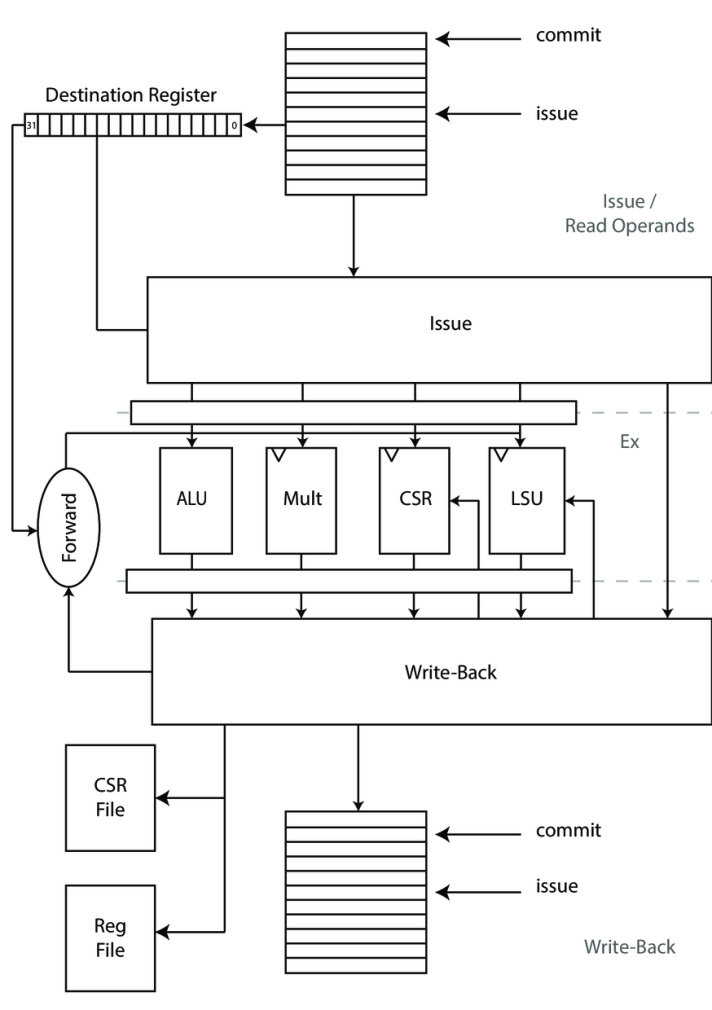
CVA6 ScoreBoard 乱序执行机制
从架构图中可以看到,
ScoreBoard贯穿了issue、execute、commit三级流水线。ScoreBoard是CVA6实现乱序执行的关键!
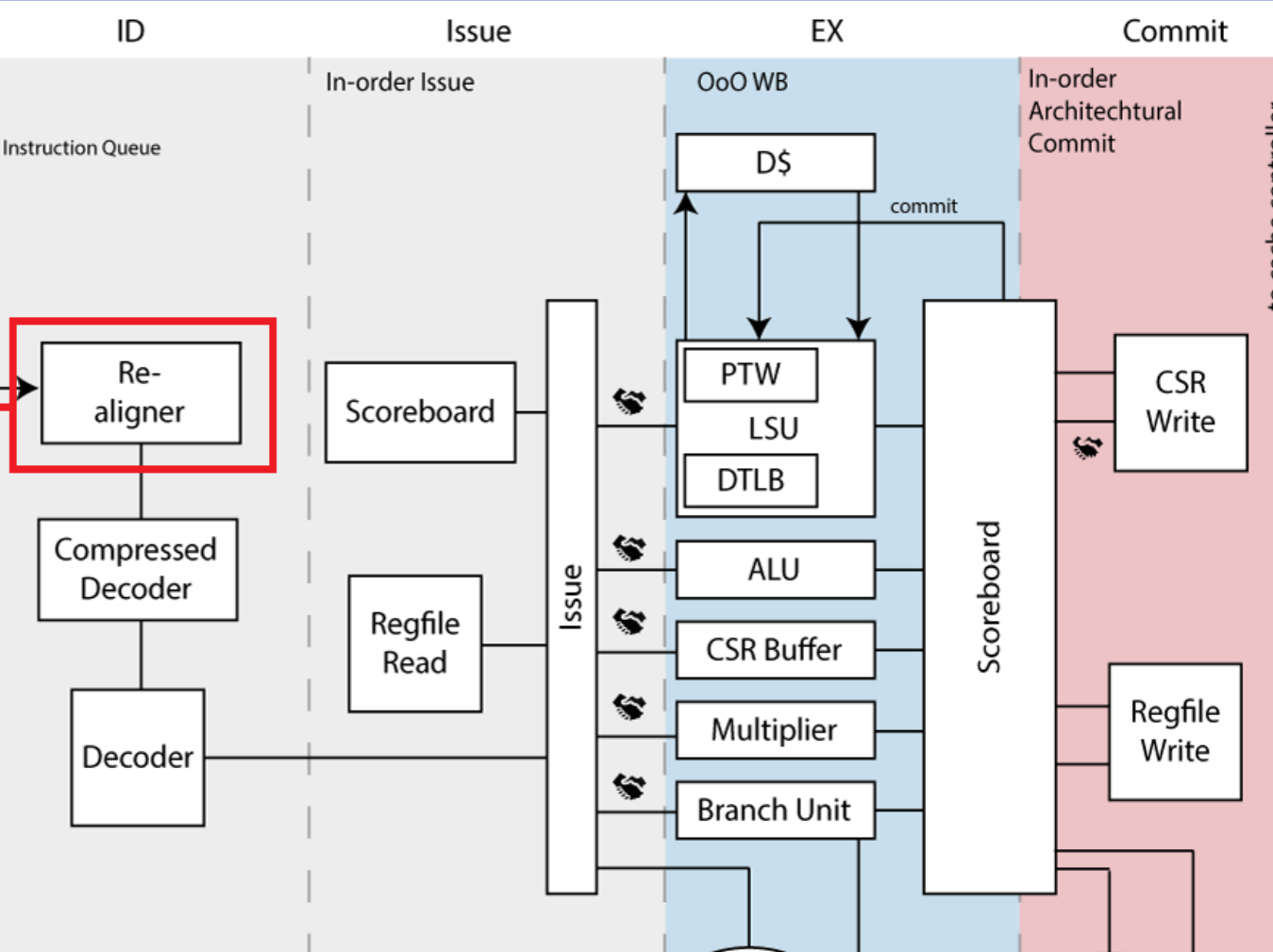
ScoreBoard 在流水线中的作用
- 决定
Issue stage中的指令是否可以发射(反压)- 操作数没有准备好
- 执行单元没有准备好
- 为
Issue stage提供操作数(bypass) - 暂存
Excute stage各个Fu执行后的结果 - 为
Commit stage提供已经完成的指令进行提交
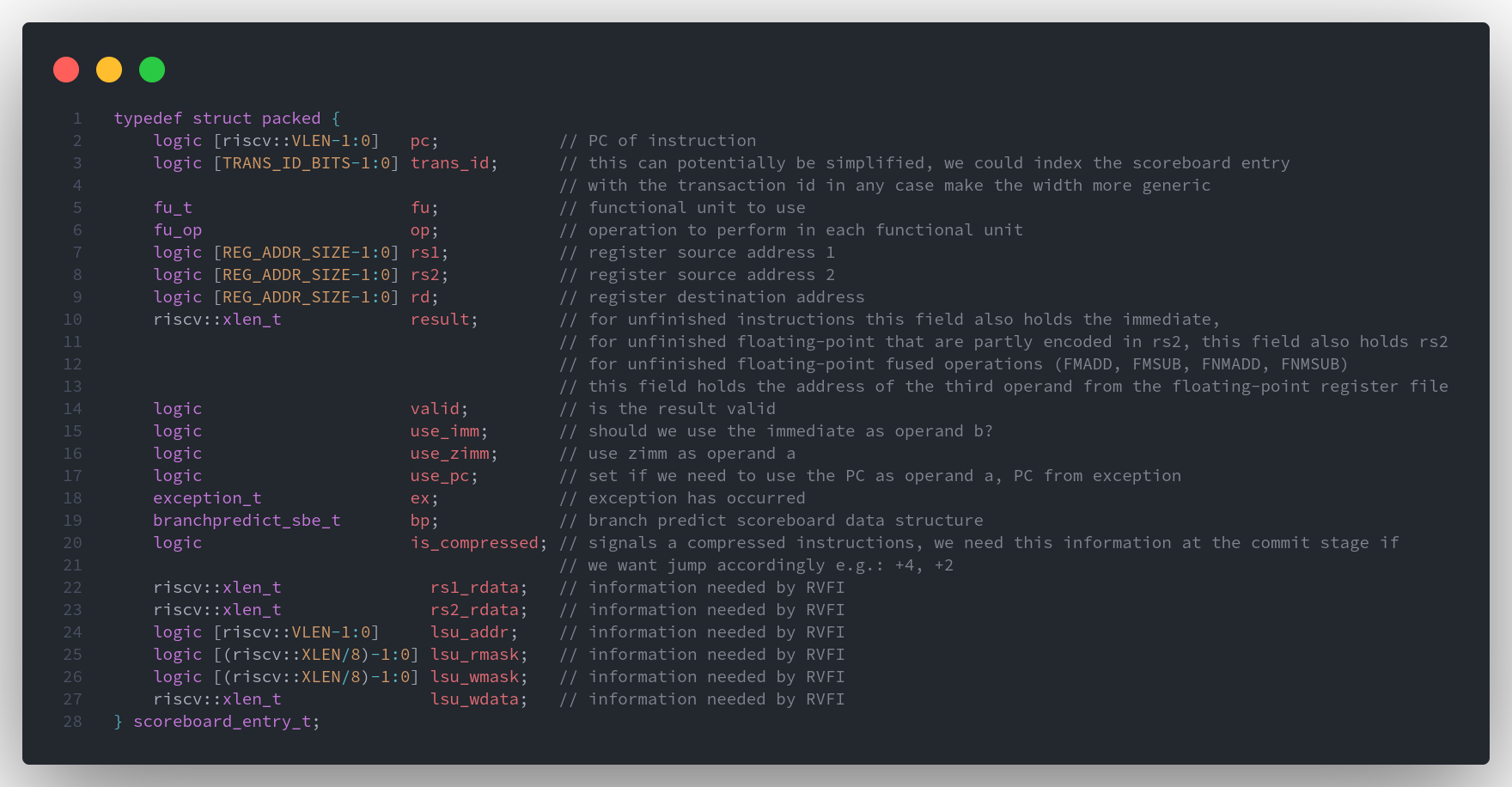
ScoreBoard_entry 类型
一条指令在经过
ID阶段后,会被译码为ScoreBoard_entry_t类型,并送往issue stage
Issue queue
代码注释为
issue queue,但其实我认为功能上更加接近rob(reorderbuffer)
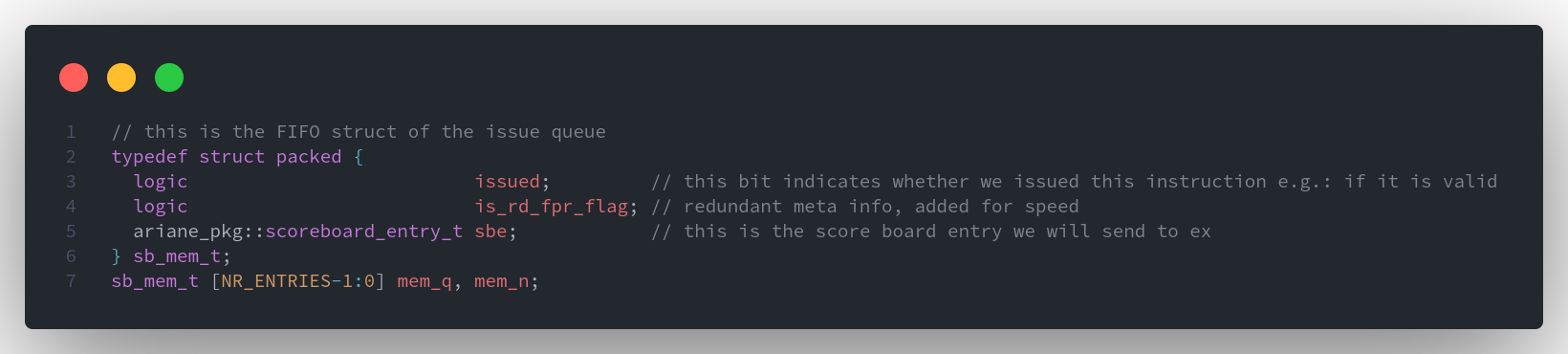
Issue queue 介绍
- Issue queue 用于存储 scoreboard_entry_t
- issue 阶段进行 push,commit 阶段进行 pop
- ex 阶段会对 queue 中具体的 scoreboard_entry_t 中的 result 和 valid 进行修改(writeback)
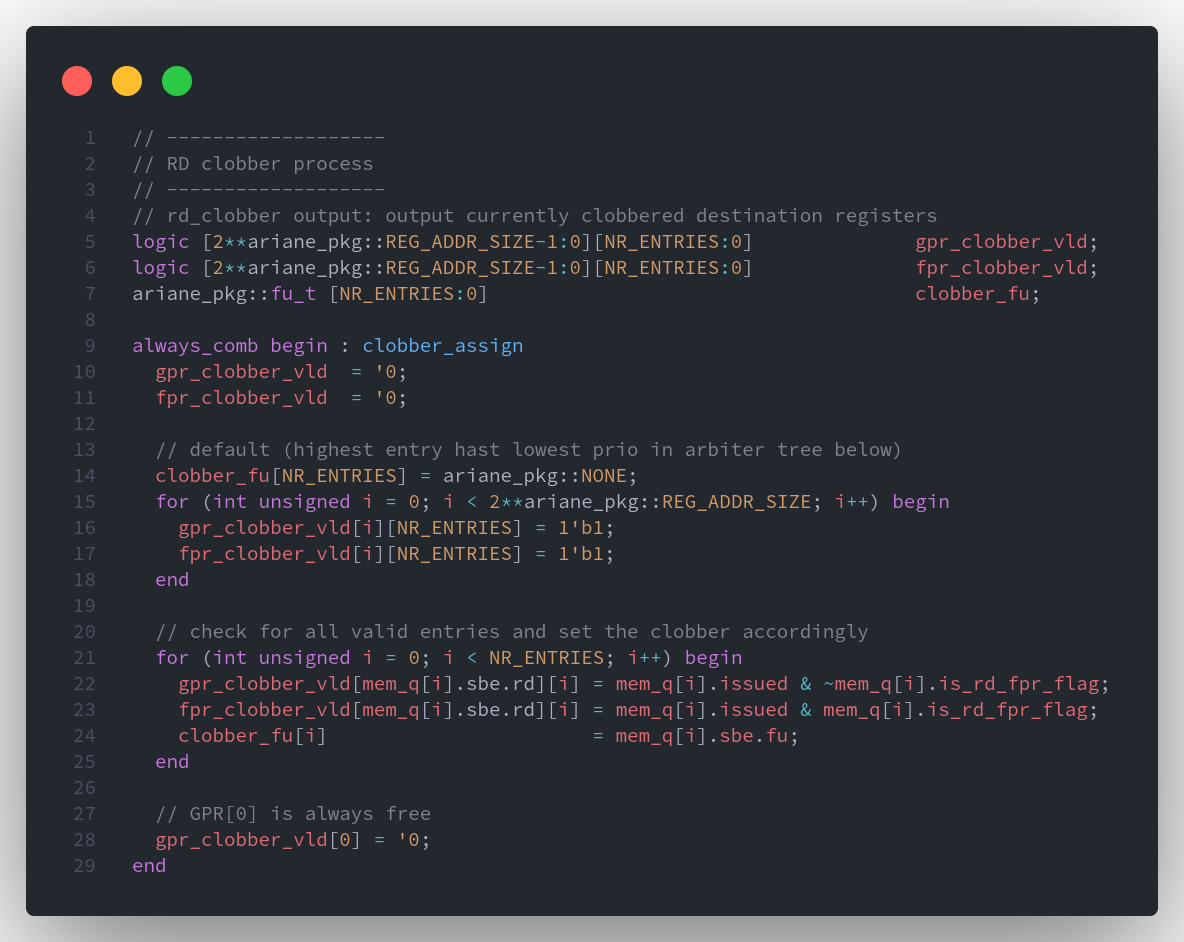
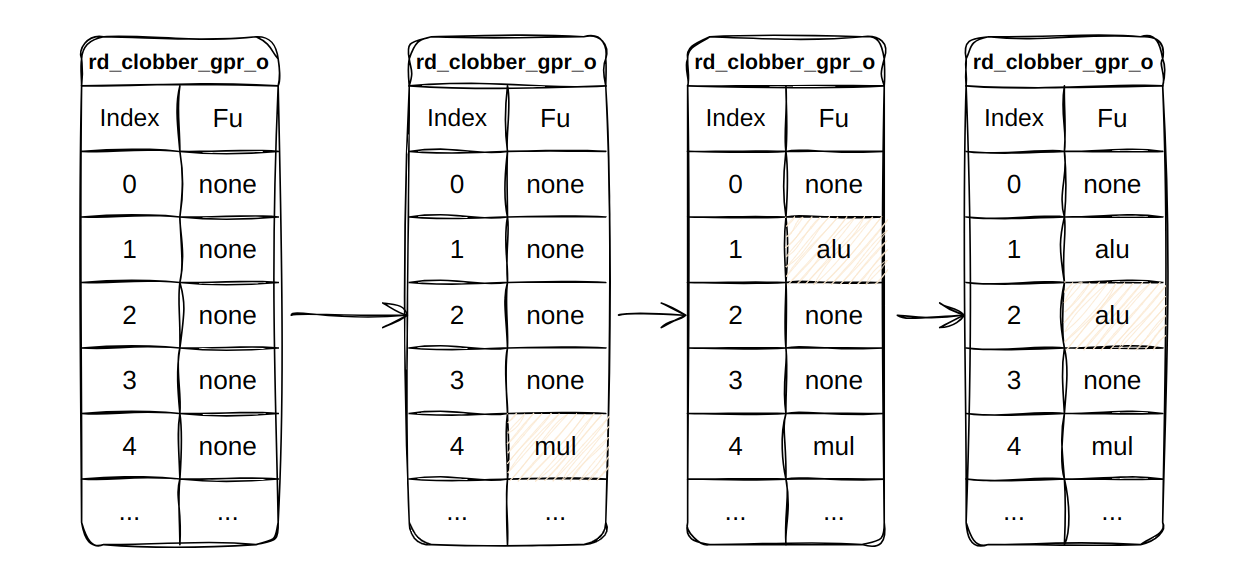
rd_clobber_gpr_o(Destination Register)
// list of clobbered registers to issue stage
`output ariane_pkg::fu_t [2**ariane_pkg::REG_ADDR_SIZE-1:0] rd_clobber_gpr_o,
rd_clobber_gpr_o 就是上面图中的 (Destination Register),用来标记 32 个通用寄存器是否被占用,以及被哪一个执行单元(fu),占用。
- 在 issue 阶段进行置 1,在 commit 阶段进行置 0
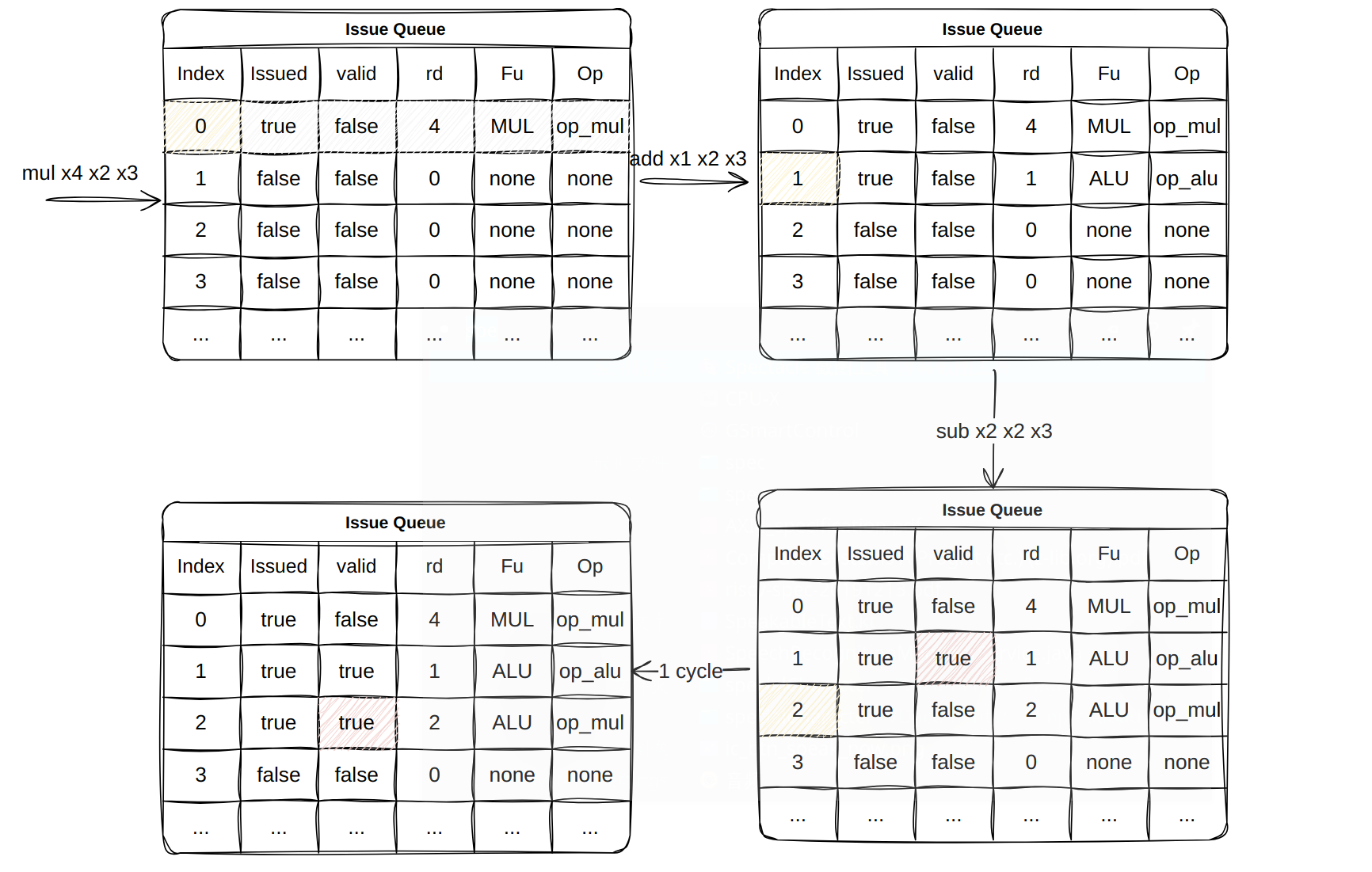
计算型指令执行过程
以最基础的计算指令,说明 CVA6 处理器乱序执行的过。更加复杂的访存操作,中断和异常不再本次文章中。
长周期指令与短周期指令的并行
假设有下面指令序列,可以明显看出序列之间没有依赖关系
1 | mul x4 x2 x3 // 5 cycle |
指令序列执行过程中 Issue Queue 和 rd_clober_gpr 的变化。
ALU 指令的 back to back 执行
CVA6 每周期发射一条指令,理想情况下的 IPC 为 1。即在执行连续的 ALU 指令时,流水线不会阻塞。
那么就必须解决,RAW、WAW、WAR 依赖
- RAW:通过 ScoreBoard 的 bypass 解决
- WAW :可以通过寄存器重命名解决(CVA6 包含一个简单寄存器重命名)
- WAR:顺序发射的情况下,没有这种情况
假设有一下指令序列,sub 和 add 存在 RAW 依赖关系
1 | add x1 x2 x3 // 1 cycle |
需要从 x1 需要从 Excute bypass 到 Issue 。
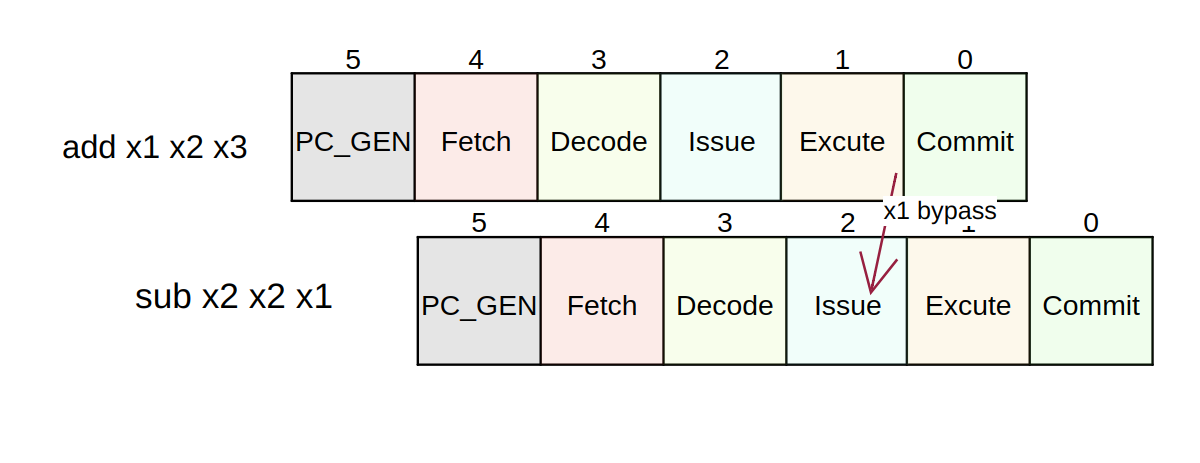
注意:op_bypass 的来源有两个
- 来自于
Excute Stage中执行单元的WriteBack Ports - 来自与
ScoreBoard中的IssueFIFO

CVA6 中具体的代码实现: